Product:
Planning Analytics Workspace
Problem:
List of versions that match other parts like the server and the workspace.
Solution:
Check the web for a list of matches.
https://www.ibm.com/support/pages/node/6519826
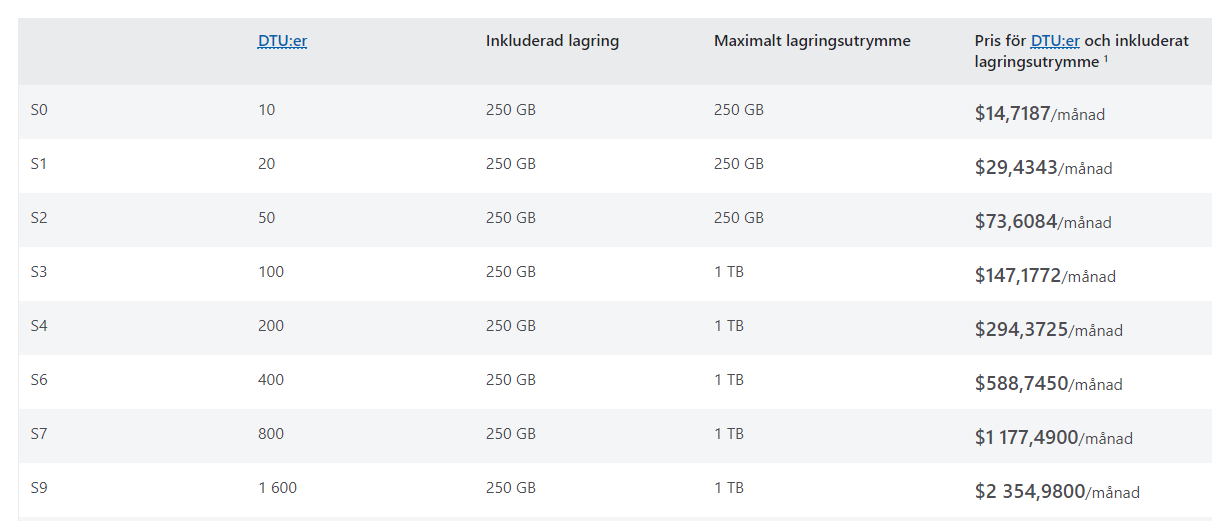
| Year.Month | PA Local TM1 Server | PA Spreadsheet Services | PA for MS Excel | PA Workspace |
|---|---|---|---|---|
| 2023.01 | 2.0.9.15 (11.8.01700.1) |
82 | * | 83 |
| 2023.02 | 2.0.9.16 (11.8.01900.1) |
83 | * | 83 |
| 2023.03 | 2.0.9.16 (11.8.01900.1) |
85 | * | 85 |
| 2023.04 | 2.0.9.16 (11.8.01900.1) |
86 | * | 86 |
| 2023.05 | 2.0.9.17 (11.8.02000.7) |
87 | * | 87 |
| 2023.06 | 2.0.9.17 (11.8.02000.7) |
88 | 88 | 88 |
| 2023.07 | 2.0.9.18 (11.8.02200.2) |
88 | 89 | 89 |
| 2023.08 | 2.0.9.18 (11.8.02200.2) |
88 | 89 | 89 |
| 2023.09 | 2.0.9.18 (11.8.02200.2) |
90 | 90 | 90 |
*IBM recommends that those who use Custom Reports and Dynamic Reports upgrade to Planning Analytics for Excel 2.0.89 immediately. For more details, see this Flash Alert.
*IBM recommends that customers upgrade to Planning Analytics Local 2.0.9.18. For more details, see this Flash Alert.
The version of PAW to use with PAX is the same version number or one above or one below. For example, if you have PAX version 2.0.50 installed, then use PAW version 2.0.49, 2.0.50 or 2.0.51.
New version for Planning Analytics Workspace, Planning Analytics for Excel comes out every 15-40 days, for Planning analytics new version comes out every 3-6 months.
More Information:
https://exploringtm1.com/planning-analytics-version-management/
https://www.tm1forum.com/viewtopic.php?t=16128
https://blog.octanesolutions.com.au/pa-paw-pax-version-conformance