Product:
Cognos Analytics 11.1.7 kit_version=11.1.7-2304260612
Issue:
How apply a fix pack for CA 11.1.7?
Solution:
Download the fix pack from IBM. https://www.ibm.com/support/pages/node/6985631
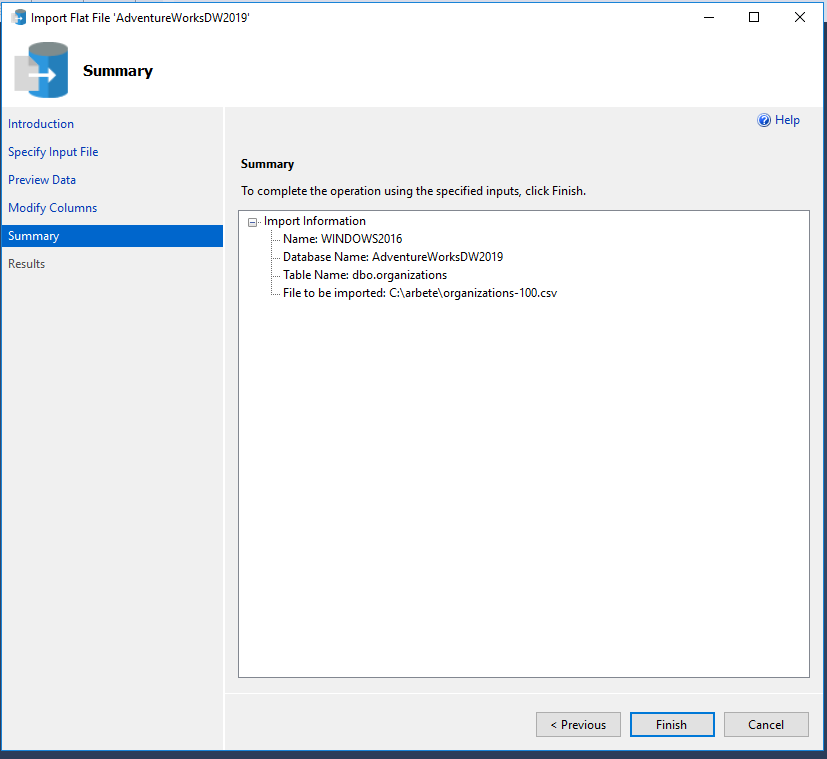
Make a backup of the content store by export it from inside Cognos Connection:
On the Cognos Analytics ‘Welcome’ dashboard, click the ‘Manage’ tab and select ‘Administration Console’.
Select the ‘Configuration’ tab and click ‘Content Administration’ on the left-hand side.
In the top right-hand side, click the icon ‘New Export’.
Specify a name for your new export (full backup contentstore) and click ‘Next’.
Click the ‘Select the entire Content Store’ radio button and select ‘Next’.
Choose the location where you want to store the deployment archive. Click ‘Next’.
Assign a password to your archive. The password must contain at least 8 characters. Re-enter your password for confirmation and then click ‘OK’.
Verify the details you have input before clicking ‘Next’.
Select ‘Save and run once’.
Specify a time when you want to run the export and click ‘Run’.
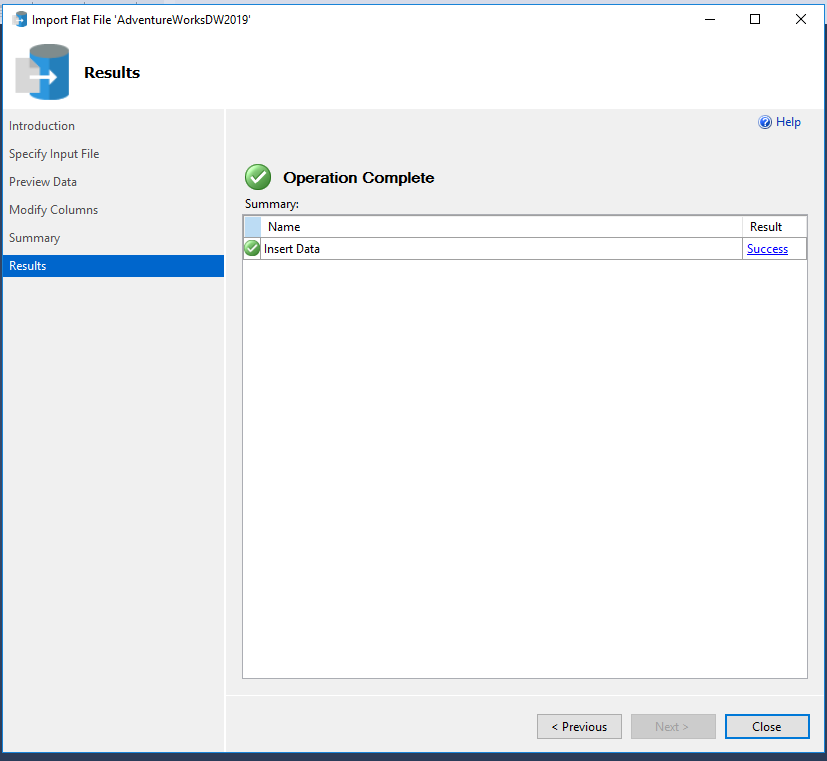
Click ‘OK’ to complete the export.
To save time, move content in folder D:\Program Files\ibm\cognos\analytics\deployment to d:\temp before the upgrade. Copy the few files you need back after the upgrade.
Backup the configuration in cognos configuration:
- Open Cognos Configuration.
- Click File > Export As.
- Select a location and enter a file name for the XML file.
- Click Save.
Make a backup of the following files to a d:\temp folder:
D:\Program Files\ibm\cognos\analytics\webcontent\planning.html
D:\Program Files\ibm\cognos\analytics\webcontent\pmhub.html
D:\Program Files\ibm\cognos\analytics\webcontent\web.config
D:\Program Files\ibm\cognos\analytics\webcontent\tm1\web\tm1web.html
D:\Program Files\ibm\cognos\analytics\webcontent\bi\planning.html
D:\Program Files\ibm\cognos\analytics\webcontent\bi\pmhub.html
D:\Program Files\ibm\cognos\analytics\webcontent\bi\web.config
D:\Program Files\ibm\cognos\analytics\webcontent\bi\tm1\web\tm1web.html
D:\Program Files\ibm\cognos\analytics\templates\ps\portal\variables_CCRWeb.xml
D:\Program Files\ibm\cognos\analytics\templates\ps\portal\variables_plan.xml
D:\Program Files\ibm\cognos\analytics\templates\ps\portal\variables_TM1.xml
D:\Program Files\ibm\cognos\analytics\configuration\cclWinSEHConfig.xml
Restore only the missing files after the installation.
Files to be preserved during an upgrade are listed in the D:\Program Files\ibm\cognos\analytics\configuration\preserve\.ca_base_preserve.txt file. Do not edit this file. Instead, edit the D:\Program Files\ibm\cognos\analytics\configuration\preserve\preserve.txt file if you want to remove or preserve certain files or directories when upgrading.
################################################################
#
# IBM Confidential
#
# IBM Cognos Products: Preserve Files by the Install
#
# (C) Copyright IBM Corp. 2017
#
# Edit this file (preserve.txt) to remove or preserve files or directories when upgrading.
#
#
# Instructions:
#
# - Edit preserve.txt before running an upgrade on an existing install.
# - Use '#' at the beginning of a line to insert a comment.
# - The keyword "exclude:" can be used to remove files inside a preserved directory (see examples below).
# - List directories or files relative to the installation root directory (see examples below).
#
#
# e.g.: To remove this file: <installdir>/media/samples.doc, add this line:
# exclude:media/samples.doc
#
# e.g.: To preserve the file <installdir>/msgsdk/cm_ldkspec.xml, add this line:
# msgsdk/cm_ldkspec.xml
#
# e.g.: To preserve the contents of the folder: <installdir>/cps/sap/webapps, add this line
# cps/sap/webapps
#
# Note on order of precedence: Files to be excluded should be specified first (before the directories which contain them).
#
################################################################
# Specify files to exclude first
# Specify files or folders to preserve
If you have changed security or use certificates, then you need to also backup all the certificates store files.
Stop the Cognos Analytics Service and close down Cognos Configuration. Stop the Apache or IIS webserver services.
Launch the downloaded installation file (analytics-installer-2.2.27-win.exe) and follow the wizard.
Choose your Language and click Next.
Choose What you want to install – for an upgrade this will be IBM Cognos Analytics click Next.
Choose to Accept the license and click Next.
Choose the location. This must be the location of your Cognos Analytics instance that you would like to upgrade and also the shortcut folder name. Click Next.
Click Yes to confirm you are Installing in the same location and are overwriting a previous installation.
Click Install at the summary screen.
When complete click Done to complete the upgrade.
Open Cognos Configuration – you will be prompted that older versions of Configuration files were found and configuration files have been upgrade to the latest version. click OK and Save your configuration.
Repeat the steps for all servers in your distributed environment, before starting the Cognos Analytics Content Manager Services first and then the rest.
Check the file D:\Program Files\ibm\cognos\analytics\cmplst.txt to see what version is installed.
More Information:
https://www.ibm.com/support/pages/ibm-cognos-analytics-11x-fix-lists
https://www.ibm.com/support/pages/how-export-entire-content-store-cognos-analytics-11
https://pmsquare.com/analytics-blog/2022/6/8/how-to-find-your-cognos-version-build-and-common-name
https://www.ibm.com/docs/en/cognos-analytics/11.1.0?topic=servers-copying-cognos-analytics-certificate-another-server
https://www.ibm.com/support/pages/how-add-3rd-party-ca-allow-ssl-between-components-ibm-cognos-analytics-11