Product:
Linux Mint
Microsoft Windows 10
Problem:
How make a bootable usb to install a OS to old computer? Old computer only have CDROM drive, and modern OS does not fit on that. They need GB of space.
Solution:
Download the ISO you need – for example Linux Mint from here:
https://www.linuxmint.com/download.php
Download software to create USB drive, like
https://etcher.balena.io/#download-etcher
How to do it:
https://youtu.be/764JLB13GjE?si=Gby6iZeC79FGZLll
Start the program balenaEtcher.
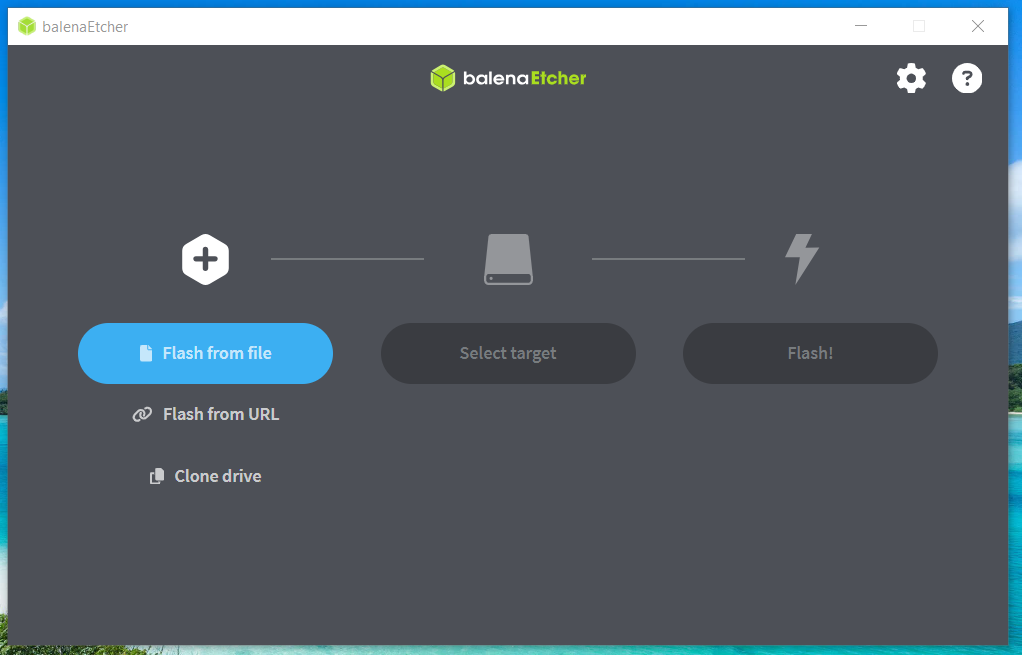
Select the iso file to use.
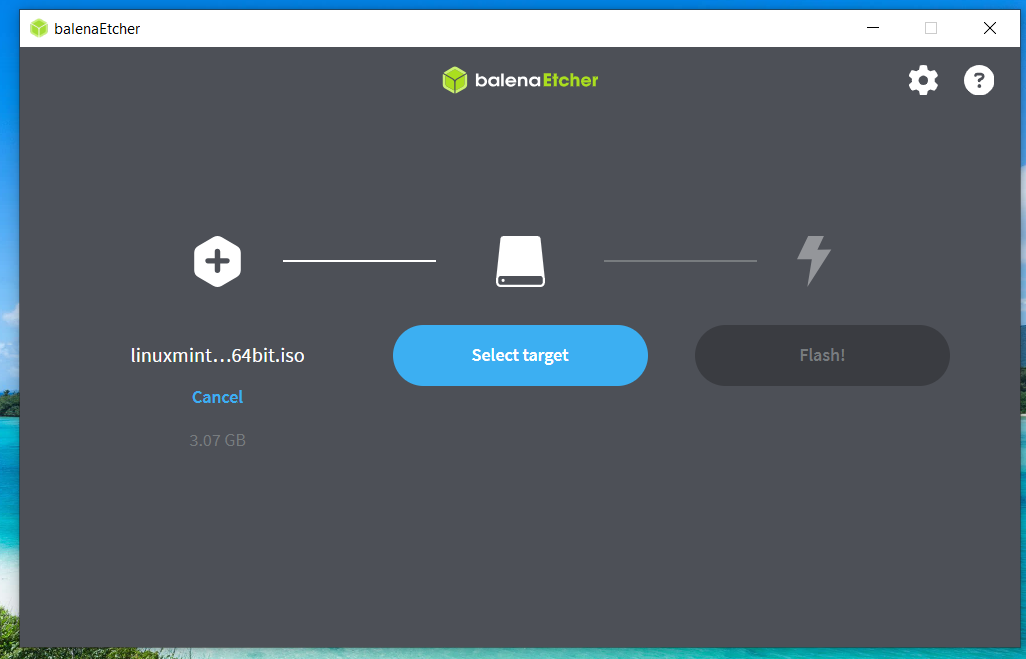
Select the USB stick to use.
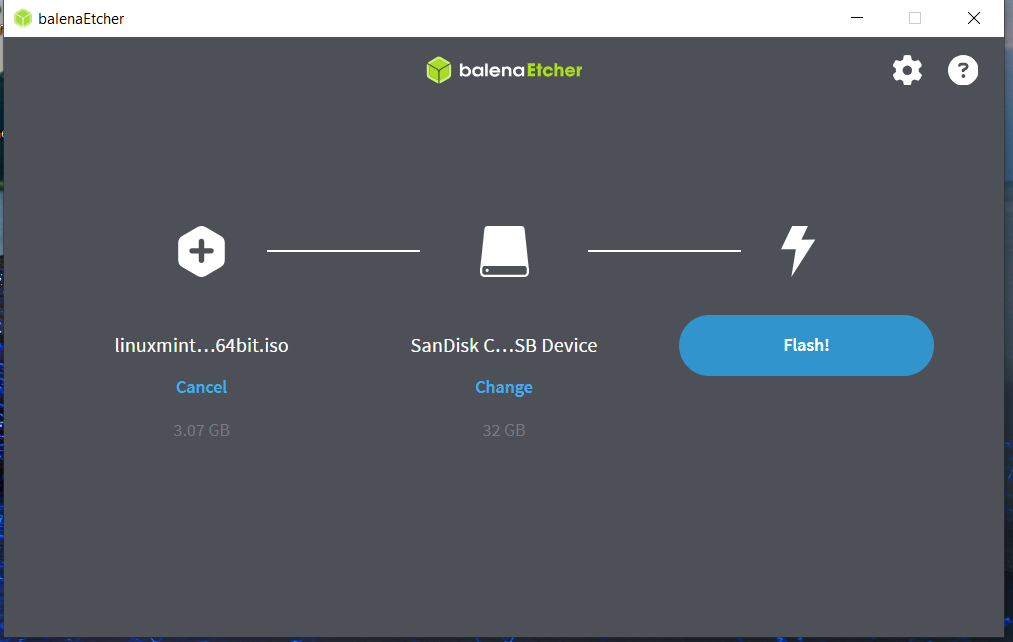
Click on Flash to create the usb media.
If you get error, reboot your laptop, and try again.
Ensure that the computer you are going to install Linux to, have in BOOT setup, that it will start from USB stick, before hard drive.
https://www.zdnet.com/article/how-to-install-linux-on-an-old-laptop/
https://itsfoss.com/install-linux-mint/
For old computers with 32 bit processor , you need to install the 32 version of linux.
https://www.linuxmint.com/edition.php?id=308
https://www.debugpoint.com/32-bit-linux-distributions/
What does the name on Windows OS ISO file mean?
This post is not made to list every possible filename there is, only summarize what other have written about the subject. They iso code may vary slightly between products and editions.
We believe that J_CPRA_X64FRE is Windows 10 Pro 64 bit.
The coding does not seem to be formally or comprehensively documented, but you can assemble hints from various scattered observations around the web.
J_CPRA_X64F looks like a short form version designed to fit in the legacy 11 character disk label from the old FAT volume label limits. J is the Windows 10 release. CPRA is the Pro edition, where the “C” is for “client” (as opposed to “server”) “PR” is for “Professional” and “A” is the variant of the professional edition (most times there is only one). X64 is the CPU architecture. F is short for FRE is a final-released (checked) build as opposed to a CHK (checked) build, used for debugging. (source: https://forums.whirlpool.net.au/archive/2468594).
The typical full version of an ISO file name is longer, including the language and region, and sometimes the target medium. For example, JM1_CCSA_X64FRE_EN-US_DV9 was the Windows 10 Technical Preview install DVD (dual layer, 8.5GB aka DVD9) and JM1_CCSA_X64FRE_EN-US_DV5 is a Windows 10 install DVD (single layer, 4.7GB, aka DVD5). EN-US is US English. X64 is for the x86 64-bit version. JM1 is a pre-release of “Redstone” (Windows 10); CCSA is the “Windows Technical Preview Edition.”
Other Windows 10 edition examples include:
CENA (Client, ENterprise, “A”)
CEDA (Client, EDucational, “A”)
You can seem some historic product to volume label mapping at https://support.microsoft.com/en-us/help/889713/how-to-determine-the-channel-that-your-copy-of-windows-server-2003-was
and also
Original CD/DVD Volume Labels for Windows
Some of the Windows 7 media labels can be found at Get Windows 7 SP1-U Media Refresh MSDN/TechNet ISO (Download or Convert) « My Digital Life. and Official Windows 7 SP1 ISO from Digital River « My Digital Life.
Windows 7 releases started with the letter “G”.
Windows 8 releases started with the letter “H”. (Windows 8 Enterprise x86 Volume Licensing ISO Leaked « My Digital Life)
Windows 10 uses the letter “J”. I would presume that “I” was skipped to avoid confusion with “1”.
The two Windows 7 ISO file names, can be explained like this:
——–

- Language of the OS. Always two letters (with one exception). Example: en, en-gb, cs, da, no, sv.
- Minor version build of the OS.
- Compile date of the OS (not of the ISO). Indicates YYMMDD-HHMM.
- Platform architechture and target. x86 = 32bit 8086-based, x64 = 32bit 8086-based with 64bit AMD-64 extensions. fre = Free, for end user. chk = Checked, debug version. Examples: x86fre, x64chk.
- SKU version. Examples: enterprise, enterprisen, professional, starter.
- Full language tag of the OS. Must match (1). Examples: en-us, en-gb, sv-se.
- Volume license identifier. Optional.
- Upgrade identifier. Optional.
- Original equipment manufacturer identifier. Optional.
- Matches (5).
- Volume label of the mounted ISO volume. Contains various codes to identify language, SKU, volume/OEM and media.
——–
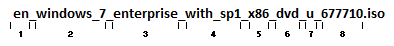
- Language of the OS. Always two letters (with one exception). Example: en, en-gb, cs, da, no, sv.
- Product name. Examples: windows_7, windows_8, windows_server_2012.
- SKU version. Examples: enterprise, enterprisen, professional, starter.
- Integrated service pack level. Optional.
- Platform architechture and target. x86 = 32bit 8086-based, x64 = 32bit 8086-based with 64bit AMD-64 extensions. chk = Checked, debug version. Examples: x86, x64chk.
- Storage media
- Update flag. The ISO was updated with some critical patch.
- Unique MSDN/Technet image number ID.
——–

- Language of the OS. Always two letters. Example: en, cs, da, no, sv.
- ?
- Single or double layer DVD. DVD5 = 4.7GB
- Product name. Win = Windows.
- SKU version. Examples: Pro, Pro KN, Ent.
- 7 With. Means it’s an integrated installation with a service pack. Combined with (7) for full service pack level information. Optional.
- Integrated service pack level. Optional.
- Platform target. 32BIT = x86, 64BIT = x64.
- Language of the OS.
- Updated ISO. Base ISO with added KB update.
- Microsoft Licensing Fulfillment
- Microsoft Part Number as it appears on the physical installation media.
https://www.betaarchive.com/forum/viewtopic.php?t=26026
More information:
https://itsfoss.com/watch-tv-channels-on-ubuntu-or-linux-mint/
https://www.tecmint.com/linux-media-center-distros/
https://www.computerhope.com/history/processor.htm
Have fun!


 click on activate. After someone have approved, go to next step.
click on activate. After someone have approved, go to next step.