Product:
Planning Analytics 2.0.9.19
Microsoft Windows 2019 server
Issue:
What does the .cub$ files in the data folder mean? They increase the zip file for the backup rather much.
Solution:
They are left over from a crashed SaveDataAll function. Did you have a hung TM1 instance recently?
They’re generated when you do a data save. The cube in memory is initially saved to the .cub$ file. If the save is successful then the .cub file is replaced by the .cub$ file and the latter is deleted.
If the file is still there then either:
– You’re currently doing a data save in which case deleting the file would be highly inadvisable; or
– It’s left over from a past failed data save, in which case it can be deleted. (you might want to take a backup of the files before you delete it)
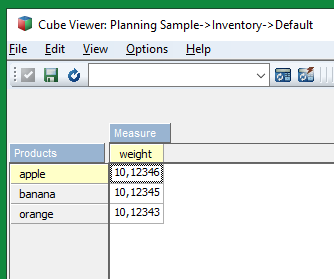
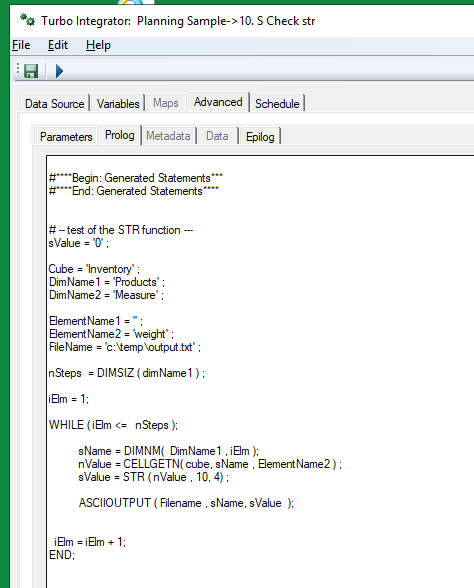
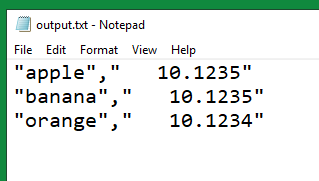
This is a TM1® rules function, valid in both TM1 rules and TurboIntegrator processes.
The number passed to the STR function must use. (period) as the decimal separator and , (comma) as the thousand separator. Any other decimal/thousand separators will cause incorrect results.
Syntax
STR(number, length, decimal)
Argument
Description
number
The number being converted to a string.
length
The length of the string. If necessary, the function inserts leading blank spaces to attain this length.
decimal
The number of decimal places to include in the function result.
by Roger·Comments Off on Illegal char <:> at index
Product:
Planning Analytics Workspace version 96
Planning Analytics 2.0.9.19
Kate Agent Version 2.0.96.1686
Issue:
When you try to use the File Manage function in PAW administration for a TM1 instance, you get a error like this:
The following administration agent error occurred – {“errorMessage”:”Illegal char <:> at index 31: D:\\TM1\\donalds budget\\Data\\;D:\\TM1\\donalds budget\\Data_SysSettings\\model_upload”,”query”:”/pakate-agent/v0/filemanager/donalds%20budget/files”,”httpStatusCode”:500}
This happens when you use….
Multiple data directories
You can specify that you want IBM TM1 Server to use multiple data directories by separating the directory names with semicolons. When you specify multiple data directories, TM1 does the following.
Accesses cubes and dimensions from each of the specified directories. If there is a duplicate object, TM1 accesses the object from the first directory specified.
Writes changes to the directory where the object is located. When you create a new object, TM1 writes to the first directory you had specified.
For example, suppose you want to store dimensions in a directory called tm1dims, and cubes in a directory called tm1cubes. You would specify the following in the Tm1s.cfg file:
DatabaseDirectory="c:\tm1dims;c:\tm1cubes"
By concatenating the two directories, you can access these objects through Server Explorer as if they were in a single location.
Solution:
Downgrade to a previous version of PAA Agent, they does not seem to have the problem.
Ask IBM Support for help.
Looks like this function is not supported in newer versions of PAW.
Specifies the data directory from which the database loads cubes, dimensions, and other objects.
This parameter is not applicable to Planning Analytics Engine.
You can list multiple data directories by separating them with semicolons.
Important: The Planning Analytics database supports multiple data directories, but Planning Analytics Administration in Planning Analytics Workspace Local does not. If you are configuring your database for Planning Analytics Workspace Local, you must specify a single database.
by Roger·Comments Off on Current configuration points to a different Trust Domain than originally configured.
Product:
Planning Analytics 2.0.9.19
Microsoft Windows 2019 Server
Issue:
After create a new Content Store database for Cognos Analytics 11, then you can not start or create new TM1 instances. You get an error like:
[Cryptography]
[ ERROR ] CAM-CRP-1315 Current configuration points to a different Trust Domain than originally configured.
[Cryptography]
[ ERROR ] The cryptography information was not generated.
or you get error
The Cryptographic information cannot be encrypted. Do you want to save the configuration in plain text?
Solution:
This happens when the Planning Analytics Local is a single-server installation, and Admin Server and Application Service are installed on the same server (same directory).
Note: Be sure to back up any files and directories before deletion
1) From the Cognos Configuration menu bar click File–>Export As
*Save in decrypted format. Click yes and save the file in a location outside Planning Analytics installation directory
**This step keeps a backup of the config file (cogstartup.xml)
2) Close Cognos Configuration
3) In Windows Services, stop all Planning Analytics services
4) From the <Planning Analytics install dir>\configuration\certs\ directory, delete the files CAMKeystore and CAMKeystore.lock
5) From the <Planning Analytics install dir>\configuration\ directory, delete the \csk directory
6) From the <Planning Analytics install dir>\configuration\ directory, delete the cogstartup.xml
7) From the <Planning Analytics install dir>\configuration\ directory, delete the file ‘caserial’ (if this file does not exist, continue with next step)
8) From the <Planning Analytics install dir>\temp\cam\ directory, delete the file ‘freshness’ (if this file does not exist, continue with next step)
9) Copy the cogstartup.xml file backup taken in Step 1 and paste in <Planning Analytics install dir>\configuration\ directory
10) Launch the Cognos Configuration
11) Save the configuration and start the Planning Analytics services
*The first save might take a few minutes to complete
Unable to save changes in Cognos Configuration. It fails during the step Generate cryptographic information with an error.
ERROR:
[Cryptography]
[ERROR ] CAM-CRP-1093 Unable to read the contents of the keystore ‘E:/ibm/cognos/tm1_64/configuration/certs\CAMKeystore’. Reason: java.io.IOException: error construct MAC: java.security.NoSuchAlgorithmException: no such algorithm: 2.16.840.1.101.3.4.2.2 for provider BC.
Resolving The Problem
Re-create the Cryptographic keys as above.
Make a backup of the “<Planning Analytics install>/tm1_64/configuration/certs” folder
Launch iKeyman from “<Planning Analytics install>/tm1_64/jre/bin” and perform the following steps in iKeyman
Click Open Button
Select configuration/certs/CAMKeyStore, and use the password
Now delete all the certificate
Select Personal Certificates and click the import
Import the pfx file
Rename the label to “encryption”
From the drop-down, select signer certificates
Import the ibmtm1.arm file from the location “bin64/ssl” and name it to ibmtm1, click OK.
Start the service “IBM Cognos TM1” from the services.msc
by Roger·Comments Off on The system cannot find the file specified
Product:
Planning Analytics Workspace 96
Microsoft Windows 2019 server
Issue:
When in PAW use the file manager function on a TM1 instance, you get a error message:
The following administration agent error occurred – {“errorMessage”:”..\\..\\..\\..\\paaAgentCache\\serversInfo.json (The system cannot find the file specified.)”,”query”:”/pakate-agent/v0/filemanager/donalds%20budget/files”,”httpStatusCode”:500}
Solution:
Check if the name have a space last in the registered windows service name.
Go to Cognos Configuration for Planning Analytics and delete the application “donalds budget ”
Edit the tm1s.cfg file with Notepad++
# Server name to register with the Admin Server. If you do not supply this parameter, TM1 names the server Local and treats it as a local server.
# Type: Optional, Static
ServerName=donalds budget
Save the file with the new name, without a space last.
Create a new instance in planning analytics configuration, name it donalds budget, and point out the folder where the config file is.
Save and start the TM1 instance.
Now the name should be registered in windows services, with the correct name.
If you have a space accidentally in the servername in the tm1s.cfg file, the Tm1 instance will not work well in PAW administrator.
Below a suggested setup in tm1s-log.properties file.
# main logging file
log4j.logger.TM1=INFO, S1
# S1 is set to be a SharedMemoryAppender
log4j.appender.S1=org.apache.log4j.SharedMemoryAppender
# Specify the size of the shared memory segment
log4j.appender.S1.MemorySize=5 MB
# Specify the max filesize
log4j.appender.S1.MaxFileSize=20 MB
# Specify the max backup index
log4j.appender.S1.MaxBackupIndex=40
# Specify GMT or Local timezone
log4j.appender.S1.TimeZone=Local
# event logging configuration
# Meeds EventLogging=T in the tm1s.cfg
# https://www.ibm.com/support/knowledgecenter/SSD29G_2.0.0/com.ibm.swg.ba.cognos.tm1_inst.2.0.0.doc/c_eventlogging.html
#log4j.logger.Event=INFO, S_Event
#log4j.appender.S_Event=org.apache.log4j.SharedMemoryAppender
#log4j.appender.S_Event.MemorySize=1 MB
#log4j.appender.S_Event.MaxFileSize=10 MB
#log4j.appender.S_Event.MaxBackupIndex=10
#log4j.appender.S_Event.Format=TM1Event
#log4j.appender.S_Event.TimeZone=Local
#log4j.appender.S_Event.File=tm1event.log
# tm1top logging configuration only in version 2.0.7 and later
# Set up TopLogging=T in the tm1s.cfg
# https://www.ibm.com/support/knowledgecenter/SSD29G_2.0.0/com.ibm.swg.ba.cognos.tm1_op.2.0.0.doc/c_pa_top_logger.html
#log4j.logger.Top=INFO, S_Top
#log4j.appender.S_Top=org.apache.log4j.SharedMemoryAppender
#log4j.appender.S_Top.MemorySize=5 MB
#log4j.appender.S_Top.MaxFileSize=10 MB
#log4j.appender.S_Top.MaxBackupIndex=20
#log4j.appender.S_Top.TimeZone=Local
#log4j.appender.S_Top.Format=TM1Top
#log4j.appender.S_Top.File=tm1top.log
# Logins file -- records every time a user logins, can be used for license evaluation or just checking user activity
log4j.logger.TM1.Login=DEBUG, S_Login
log4j.appender.S_Login=org.apache.log4j.SharedMemoryAppender
log4j.appender.S_Login.MemorySize=5 MB
log4j.appender.S_Login.MaxFileSize=10 MB
log4j.appender.S_Login.MaxBackupIndex=20
log4j.appender.S_Login.TimeZone=Local
log4j.additivity.TM1.Login=false
log4j.appender.S_Login.File=tm1login.log
# memory logging configuration
log4j.logger.TM1.Server.Memory=INFO, S_Memory
log4j.appender.S_Memory=org.apache.log4j.SharedMemoryAppender
log4j.appender.S_Memory.MemorySize=5 MB
log4j.appender.S_Memory.MaxFileSize=20 MB
log4j.appender.S_Memory.MaxBackupIndex=10
log4j.appender.S_Memory.TimeZone=Local
log4j.appender.S_Memory.File=tm1memory.log
# it's good to have Locks details -- provides the names of the locked objects
# putting to a separate file to have a cleaner main log as PaW rollbacks requests a lot
log4j.logger.TM1.Lock.Exception=DEBUG, S_Lock
log4j.additivity.TM1.Lock.Exception=false
log4j.appender.S_Lock=org.apache.log4j.SharedMemoryAppender
log4j.appender.S_Lock.MemorySize=5 MB
log4j.appender.S_Lock.MaxFileSize=20 MB
log4j.appender.S_Lock.MaxBackupIndex=20
log4j.appender.S_Lock.TimeZone=Loca
log4j.appender.S_Lock.File=tm1lock.log
In future version you have to do something else, probably you need to run some external schedule program that talk REST API to tm1 servers, like TM1Py (cubewise.com) .. and then monitor the TM1 REST API to know when other external program should start.
From a external python script can you send email and start a TM1 TI process (with REST API) , but how do you activate them from inside TM1 TI without use of the ExecuteCommand?
Only option is ExecuteHttpRequest, described below: (but that means that the other application must have a REST API support)
This function executes an HTTP request. It supports HTTP methods GET, POST, PATCH, PUT and DELETE.
The HTTP response is cached in memory. A response consists of a status code, a number of headers and a body, any of which can be queried by using the corresponding TurboIntegrator functions: HttpResponseGetStatusCode, HttpResponseGetHeader, and HttpResponseGetBody.
The Planning Analytics Engine only keeps one HTTP response at a time. A new successful HTTP request execution update and overwrites the cached response.
The Planning Analytics Engine only keeps the first 100 KB of a response body and discards the rest. This prevents running out of evaluation memory for strings.
For convenience, the engine reuses the cookie it found in the previous responses in new requests when the Cookie header is absent.
It may exist in some version of TM1. Unclear in the IBM documentation. Below links about Tm1 Rest Api
Introduction
You can use the IBM® Cognos® TM1® REST API to perform create, read, update, and delete operations on TM1 data by using standards that are defined by OData Version 4 (http://www.odata.org/documentation/).
Overview
The IBM Cognos TM1 REST API provides an Open Data Protocol (OData) Version 4 compliant interface to an IBM Cognos TM1 server, which allows clients to query and update data sources that are hosted by the IBM Cognos TM1 Server.
Installation and configuration
After you install IBM Cognos TM1 with the procedures that are described in the Planning Analytics Installation and Configuration documentation, you must enable the use of TM1 REST APIs.
Metadata
The Entity Data Model (EDM) defines the TM1 data model that is based on OData Version 4.0 Part 3: Common Schema Definition Language (CSDL). It defines the TM1 data model in a common way so that OData clients can understand and manipulate the model.
Representing TM1 data
The OData standard provides a uniform, commonly accepted method of interacting with data by using a REST interface.
Managing TM1 database assets with Git
You can use Git source control to deploy database assets such as cubes, books, and views. As an administrator of a TM1 database, you can deploy database assets between environments (for example, from development to production) without stopping the database or manually copying and pasting assets. The source specifications of models and their database assets are created and managed with Git commands. You can see the structure of the database assets in Git and use Git commands to add and remove versions of your assets.
The TM1 Admin Server
Learn all about the IBM TM1 Admin Server here. To access the metadata of the TM1 Admin Server, use http://<adminserver>:5895/api/v1/$metadata or https://<adminserver>:5898/api/v1/$metadata.
ExecuteCommand is going away in v12 (no interaction with OS in containers) so any external interaction (e.g. emails) will need another way to talk to something
TM1RunTI will not work in v12 either (as well as anything else using C API) and would leave a gap in PA orchestration capability, requiring some external tool to connect 2 PA databases. ExecuteHttpRequest would allow using TM1 Rest Api to achieve the same functionality
But does it exist a scheduler that talk REST API? Power Automate can run Python or PowerShell code where you can write REST API (but Power Automate run IronPython version 2.7 or 3.4, that does not work well with latest tm1py).
by Roger·Comments Off on Windows explorer (process id: 4860) error when install 7-zip
Product:
Microsoft Windows 2019 server
7 zip program
Problem:
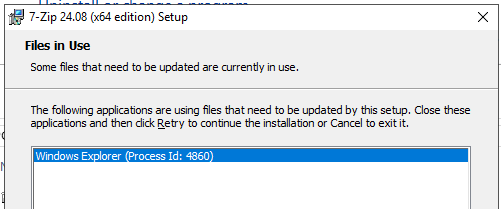
During upgrade of 7zip you run the MSI installer, it gives a error “some files that need to be updated are currently in use”. To close all windows explorer windows does not help.
if you get above error, it can be needed with a restart of the windows server to complete the installation.
Solution:
Uninstall previous version of 7-zip program before you install the new version.
7-Zip Extra: standalone console version, 7z DLL, Plugin for Far Manager
Go to control panel – program and features – right click on old 7zip version and select uninstall.
Make the new 7zip msi file accessible from inside the windows server, and run it to install it.
Click Next in all dialogs, ensure that the path is C:\Program Files\7-Zip.
When installation is done, check in control panel that you have correct version installed.
If you want to use a command file, there in the 7-zip extra exist a 7za.exe file you can use in a folder. Download the 7z2408-extra.7z file and unzip it. Place the needed files on the server where it should be run.
And create batch files that interact with it, with parameter like this;
Usage: 7za <command> [<switches>...] <archive_name> [<file_names>...] [@listfile]
<Commands>
a : Add files to archive
b : Benchmark
d : Delete files from archive
e : Extract files from archive (without using directory names)
h : Calculate hash values for files
i : Show information about supported formats
l : List contents of archive
rn : Rename files in archive
t : Test integrity of archive
u : Update files to archive
x : eXtract files with full paths
<Switches>
-- : Stop switches and @listfile parsing
-ai[r[-|0]][m[-|2]][w[-]]{@listfile|!wildcard} : Include archives
-ax[r[-|0]][m[-|2]][w[-]]{@listfile|!wildcard} : eXclude archives
-ao{a|s|t|u} : set Overwrite mode
-an : disable archive_name field
-bb[0-3] : set output log level
-bd : disable progress indicator
-bs{o|e|p}{0|1|2} : set output stream for output/error/progress line
-bt : show execution time statistics
-i[r[-|0]][m[-|2]][w[-]]{@listfile|!wildcard} : Include filenames
-m{Parameters} : set compression Method
-mmt[N] : set number of CPU threads
-mx[N] : set compression level: -mx1 (fastest) ... -mx9 (ultra)
-o{Directory} : set Output directory
-p{Password} : set Password
-r[-|0] : Recurse subdirectories for name search
-sa{a|e|s} : set Archive name mode
-scc{UTF-8|WIN|DOS} : set charset for console input/output
-scs{UTF-8|UTF-16LE|UTF-16BE|WIN|DOS|{id}} : set charset for list files
-scrc[CRC32|CRC64|SHA256|SHA1|XXH64|*] : set hash function for x, e, h commands
-sdel : delete files after compression
-seml[.] : send archive by email
-sfx[{name}] : Create SFX archive
-si[{name}] : read data from stdin
-slp : set Large Pages mode
-slt : show technical information for l (List) command
-snh : store hard links as links
-snl : store symbolic links as links
-sni : store NT security information
-sns[-] : store NTFS alternate streams
-so : write data to stdout
-spd : disable wildcard matching for file names
-spe : eliminate duplication of root folder for extract command
-spf[2] : use fully qualified file paths
-ssc[-] : set sensitive case mode
-sse : stop archive creating, if it can't open some input file
-ssp : do not change Last Access Time of source files while archiving
-ssw : compress shared files
-stl : set archive timestamp from the most recently modified file
-stm{HexMask} : set CPU thread affinity mask (hexadecimal number)
-stx{Type} : exclude archive type
-t{Type} : Set type of archive
-u[-][p#][q#][r#][x#][y#][z#][!newArchiveName] : Update options
-v{Size}[b|k|m|g] : Create volumes
-w[{path}] : assign Work directory. Empty path means a temporary directory
-x[r[-|0]][m[-|2]][w[-]]{@listfile|!wildcard} : eXclude filenames
-y : assume Yes on all queries
This code part will list the servers on localhost (from the tm1py utils lib)
(you need to adjust the code to make the things you want)
import csv
import http.client as http_client
import json
import ssl
from enum import Enum, unique
from io import StringIO
from typing import Any, Dict, List, Tuple, Iterable, Optional, Generator, Union, Callable
from urllib.parse import unquote
import os
import sys
from datetime import datetime
from TM1py.Services import TM1Service
import requests
from mdxpy import MdxBuilder, Member
from requests.adapters import HTTPAdapter
from TM1py.Exceptions.Exceptions import TM1pyVersionException, TM1pyNotAdminException, TM1pyNotDataAdminException, \
TM1pyNotSecurityAdminException, TM1pyNotOpsAdminException, TM1pyVersionDeprecationException
try:
import pandas as pd
import numpy as np
_has_pandas = True
except ImportError:
_has_pandas = False
# --- parameters and settings
PORTS_TO_EXCLUDE = []
# TM1 connection settings (IntegratedSecurityMode = 1 )
ADDRESS = 'localhost'
USER = 'admin'
PWD = 'apple'
# ===== define a function to be called in the code
def get_all_servers_from_adminhost(adminhost='localhost', port=None, use_ssl=False) -> List:
from TM1py.Objects import Server
""" Ask Adminhost for TM1 Servers
:param adminhost: IP or DNS Alias of the adminhost
:param port: numeric port to connect to adminhost
:param ssl: True for secure connection
:return: List of Servers (instances of the TM1py.Server class)
"""
if not use_ssl:
conn = http_client.HTTPConnection(adminhost, port or 5895)
else:
conn = http_client.HTTPSConnection(adminhost, port or 5898, context=ssl._create_unverified_context())
request = '/api/v1/Servers'
conn.request('GET', request, body='')
response = conn.getresponse().read().decode('utf-8')
response_as_dict = json.loads(response)
servers = []
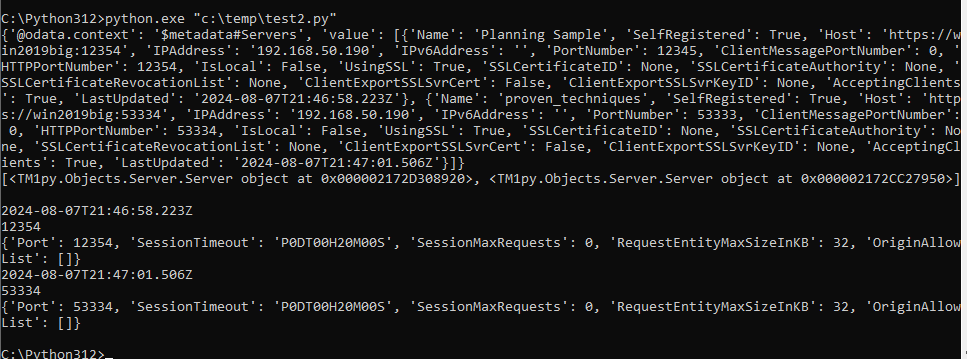
print (response_as_dict) # --- as inside function will not show ---
for server_as_dict in response_as_dict['value']:
server = Server(server_as_dict)
servers.append(server)
return servers
# ===== end of function by go back to beginning of line
# get TM1 models registered with the admin server
tm1_instances_on_server = get_all_servers_from_adminhost(ADDRESS, None, True)
# --- show the list of servers with data as dict
print (tm1_instances_on_server)
# --- for each item in list do this
for tm1_instance in tm1_instances_on_server:
# get TM1 server information
port = tm1_instance.http_port_number
# --- show one value for that server from a dict
print (tm1_instance.last_updated)
print (port)
if port in PORTS_TO_EXCLUDE:
continue
ssl = tm1_instance.using_ssl
# --- connect to the tm1 server to get some more values
tm1 = TM1Service(address=ADDRESS, port=port, user=USER, password=PWD, namespace='', gateway='', ssl=ssl)
# --- use the function
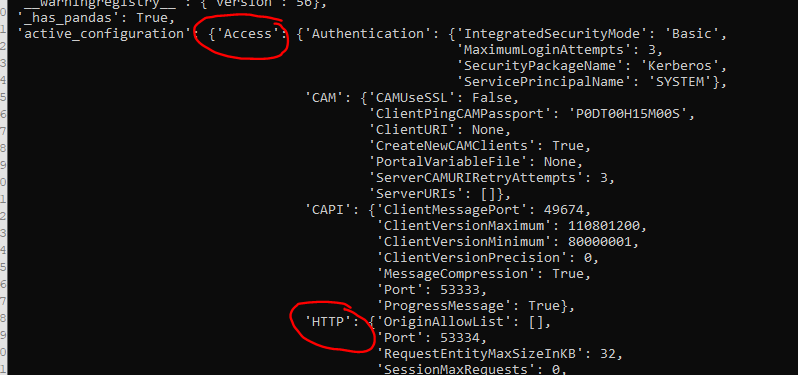
active_configuration = tm1.server.get_active_configuration()
# print (active_configuration)
print (active_configuration['Access']['HTTP'])
The last print line use more than one element to find the value to show.
print (tm1_instances_on_server) show the content of that variable, to be a list of dictionary’s.
All print statement in code, will be a line in the terminal window shown above. Use print to debug you code when you develop.
print (active_configuration[‘Access’][‘HTTP’]) , you need to add the elements of the other lists inside the list, to get a value.
Traceback (most recent call last):
File “c:\temp\test2.py”, line 106, in <module>
print (active_configuration[‘Access’][‘Administration’])
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^
KeyError: ‘Administration’ = you get a error if the key does not exist in the combo object of list and dict.
A Python dictionary (aka dict) is a series of key-value pairs referenced by key name. Dicts are delimited by curly braces. Key-value pairs are separated by commas. A key is separated from its value by a colon.
A list is an ordered collection of items, whereas a dictionary is an unordered data collection in a key: value pair. Elements from the list can be accessed using the index, while the elements of the dictionary can be accessed using keys.
Add this to the code to get a better view of the options:
from pprint import pprint
pprint (vars())
Above you can see the keys you can use to list the values in the print statement from the dict/list.
print (active_configuration[‘Access’][‘CAM’][‘ClientPingCAMPassport’]) will give you the value P0DT00H15M00S.
import json
from types import SimpleNamespace
data = '{"name": "John Smith", "hometown": {"name": "New York", "id": 123}}'
# Parse JSON into an object with attributes corresponding to dict keys.
x = json.loads(data, object_hook=lambda d: SimpleNamespace(**d))
print(x.name, x.hometown.name, x.hometown.id)
Create a python script similar to below ( you need to change values to point to your tm1 server instance ):
# import the modules needed
import os
from TM1py.Services import TM1Service
# Parameters for connection - python is case sensitive
USER = "admin"
PWD = "apple"
namespace = ""
ADDRESS = "192.168.50.190"
gateway = ""
PORT = 12354
SSL = True
#Connect to the TM1 instance
tm1 = TM1Service(address=ADDRESS, port=PORT, user=USER, password=PWD, ssl=SSL)
# where to check in cube
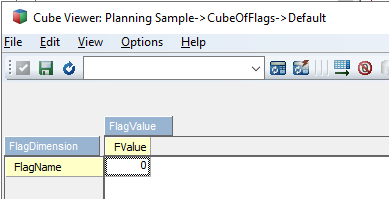
cube_name = 'CubeOfFlags'
elementname1 = "FlagName"
elementname2 = "FValue"
elementstr = elementname1 + "," + elementname2
values2 = tm1.cubes.cells.get_value (cube_name=cube_name, elements = elementstr, element_separator = ',')
# only to debug the code - it will show the value in terminal window
print(values2)
# in our example we use a bat file to run
# you need to use \\ in paths with python
testfilename = "c:\\temp\\testrun.cmd"
# execute the process if larger than zero
if values2 != None :
if values2 > 0 :
print ("this is more than zero")
# get the process to run
os.system (testfilename)
# set the value to zero in the cube
# so we do not run this process again
# cellset to store the new data
cellset = {}
# Populate cellset with coordinates and value
cellset[( elementname1 , elementname2 )] = 0
# send the cellset to TM1
tm1.cubes.cells.write_values( cube_name , cellset)
# end of code
The line indent is important in python, that tells what code to run when the if statement is true.
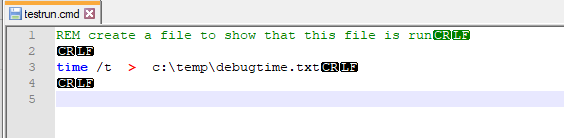
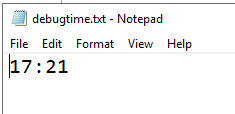
To test we created a cmd file with this code – will create a txt file with the time in it.
When run it will create a txt file with this content:
You should be able to replace above with a cmd file that does what you want.
There are better ways to do this – please try out yourself.
Schedule the python script to check the cube every five minutes with a schedule program like:
IBM Cognos Command Center provides self-service process automation. Through a single interface, it enables you to view and run automated processes on an ad hoc basis, and diagnose and address issues much more quickly. The solution reduces the complexity of working in diverse software environments and brings you greater simplicity and control….
str = None, element_separator: str = ‘,’, hierarchy_separator: str = ‘&&’, hierarchy_element_separator: str = ‘::’, **kwargs) → str | float
Returns cube value from specified coordinates
Parameters
• cube_name – Name of the cube
• elements – Describes the Dimension-Hierarchy-Element arrangement – Example: “Hierarchy1::Element1 && Hierarchy2::Element4, Element9, Element2” – Dimensions are not specified! They are derived from the position. – The , separates the element-selections
• dimensions – List of dimension names in correct order
• sandbox_name – str
• element_separator – Alternative separator for the element selections
• hierarchy_separator – Alternative separator for multiple hierarchies
• hierarchy_element_separator – Alternative separator between hierarchy name and
element name
Write value into cube at specified coordinates
Parameters
• value – the actual value
• cube_name – name of the target cube
• element_tuple – target coordinates
• dimensions – optional. Dimension names in their natural order. Will speed up the execution!
• sandbox_name – str