Product:
Planning Analytics 2.1.10
Microsoft Windows 2022 server
Planning analytics for excel ( IBM_PAfE_x86_2.0.100.3.xll )
Issue:
How do i work with a old TM1 perspective report in PAFE (PAX)?
Solution:
Create a common file share e.g \\server\pax\master (where all users that should update xlsm files should have access)
To take a existing TM1 perspective websheet to work with it in pafe (pax) you need to convert it.
Open PAFE in excel.
Ensure that you have a open blank workbook in Excel.
Ensure that you have “trust access to the VBA project object model” set.

In IBM Planning Analytics ribbon in Excel click on Options.
Scroll down to “upgrade action buttons”
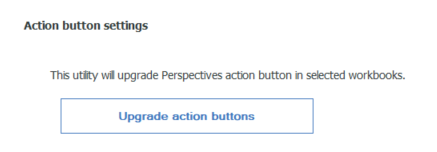
Click upgrade action buttons.
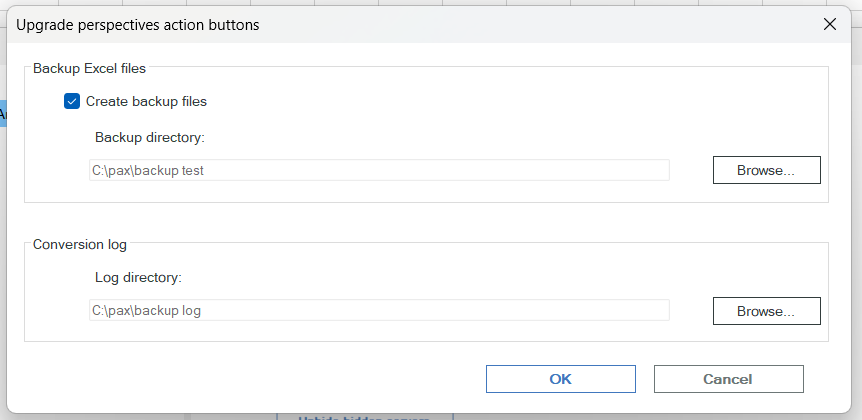
Fill in a local folder and click OK.
Select you TM1 server connection – and login.
Go down to the folder where you have your report you want to convert, select it and click upgrade.
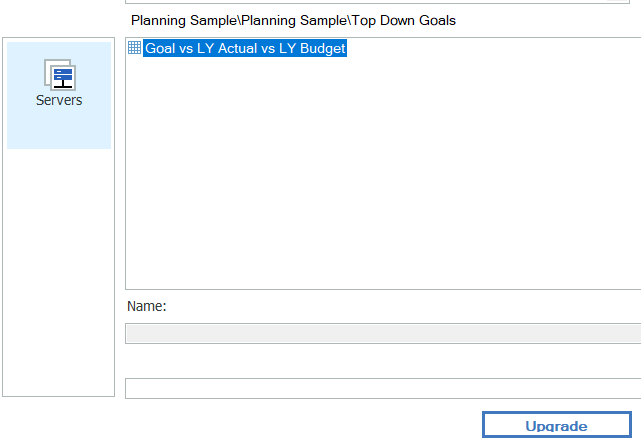
This will change the report.
Click OK
Close Excel.
Start TM1 perspective.
Login to your TM1 instance.
Explore you websheet under applications.
Open your websheet into excel, by click on it.
Inside Excel, go to Save As, and save the fil in your folder \pax\master as a .xlsm file.
Name the file to same name as your report show in TM1 applications.
Close Excel.
Start PAFE in Excel again.
Go to file – open – and open the .xlsm file you have saved above.
Click on Connect button in the IBM Planning Analytics Ribbon.
Select you TM1 server and your TM1 instance to connect.
Now you should have the report in PAFE, and on the right side you have a workbook tab. Here you can expand “action buttons” and change the existing buttons in your old Tm1 Perspective report.
After you have done any changes in the spread sheet, save it to the shared folder or a temporary local folder.
Use Excel format settings to change the text size in buttons etc.
When you are done, click on the Publish icon.
Then select under what folder you want to store the websheet.
This websheet will be visible in both TM1WEB and PAW.
Exit Excel.
When you work with PAFE (PAX) reports, you need to start from a xlsm file you have stored yourself.
(There are other ways to work with websheet in PAFE, above is a suggestion).
More Information:
PAfE Reporting Hints – QueBIT
https://exploringtm1.com/how-to-upgrade-install-planning-analytics-for-excel-pax/
https://quebit.com/askquebit/ibm-planning-analytics-for-excel-quick-start/
https://exploringtm1.com/how-to-download-ibm-planning-analytics-for-excel-from-planning-analytics-workspace/
https://www.ibm.com/docs/en/planning-analytics/2.0.0?topic=tf-tm1-worksheet-functions-in-planning-analytics-microsoft-excel