Product:
Cognos Analytics 11.0.12
Microsoft Windows 2016 server
Problem:
How limit the login to Cognos Connection to only to groups in the LDAP (active directory)?
Solution:
Use the LDAP connector in Cognos Configuration, and limit the users to be able to login only if they belong to two CN.
The “User Lookup” is used when you do not use SSO, and you let the BI (CA11) prompt the user for the user name and password. Change this to include the groups that the person must be part of to be able to login. Below a example how it can be;
(&(|(legacyuid=${userID})(uid=${userID}))(status=ACTIVE)(|(memberof=cn=Cognos_TM1_Contributor,cn=Cognos Groups,cn=UserGroups,ou=Global,o=CompanyA.com)(memberof=cn=Cognos_TM1_Modeler,cn=Cognos Groups,cn=UserGroups,ou=Global,o=CompanyA.com)))
“External identity mapping” is only used when you use SSO from IIS, to login to the BI server (CA11). You should change this to cover the same groups as the other one to make it act the same if it is using SSO or not.
(&(|(legacyuid=${replace(${environment(“REMOTE_USER”)},”CompanyA\\”, “”)})(uid=${replace(${environment(“REMOTE_USER”)},”CompanyA\\”, “”)}))(status=ACTIVE)(|((memberof=cn=Cognos_TM1_Contributor,cn=Cognos Groups,cn=UserGroups,ou=Global,o=CompanyA.com)(memberof=cn=Cognos_TM1_Modeler,cn=Cognos Groups,cn=UserGroups,ou=Global,o=CompanyA.com)))
In above lines, the user that is part of group Cognos_TM1_Contributor or Cognos_TM1_Modeler in LDAP, can login to Cognos. Good if you have a CA11 server setup, that only authenticate users that should use TM1(Planning Analytics 2.x).
(status=ACTIVE)
Check that the user is active in LDAP
legacyuid=${userID}
Compare the userid with the LDAP field Legacyuid
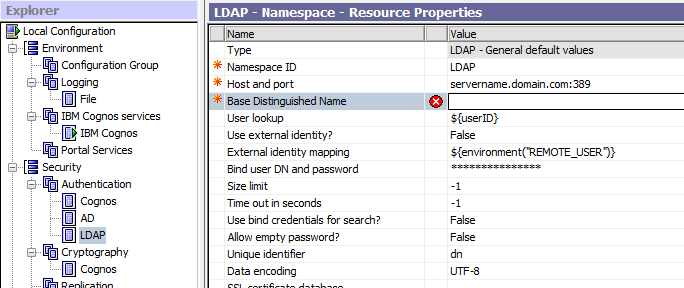
You have to change cn= and ou= values to match your LDAP setup.
Base Distinguished Name, should be the root of the LDAP directory.
How setup LDAP (from the web)
In every location where you installed Content Manager, open IBM Cognos Configuration.
In the Explorer window, under Security, right-click Authentication, and then click New resource > Namespace.
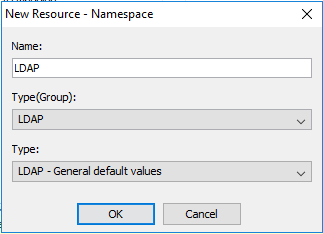
In the Name box, type a name for your authentication namespace. LDAP
In the Type list, click the appropriate namespace and then click OK.
The new authentication provider resource appears in the Explorer window, under the Authentication component.
In the Properties window, for the Namespace ID property, specify a unique identifier for the namespace. Should be same as namespace name.
Specify the values for all other required properties to ensure that IBM Cognos components can locate and use your existing authentication provider.
If you want the LDAP authentication provider to bind to the directory server by using a specific Bind user DN and password when you perform searches, then specify these values.
If no values are specified, the LDAP authentication provider binds as anonymous.
If external identity mapping is enabled, Bind user DN and password are used for all LDAP access. If external identity mapping is not enabled, Bind user DN and password are used only when a search filter is specified for the User lookup property. In that case, when the user DN is established, subsequent requests to the LDAP server are run under the authentication context of the user.
If you do not use external identity mapping, use bind credentials for searching the LDAP directory server by doing the following step:
Ensure that Use external identity is set to False.
Set Use bind credentials for search to True.
Specify the user ID and password for Bind user DN and password.
If you do not specify a user ID and password, and anonymous access is enabled, the search is done by using anonymous.
Check the mapping settings for the required objects and attributes.
Depending on the LDAP configuration, you may have to change some default values to ensure successful communication between IBM Cognos components and the LDAP server.
LDAP attributes that are mapped to the Name property in Folder mappings, Group mappings, and Account mappings must be accessible to all authenticated users. In addition, the Name property must not be blank.
From the File menu, click Save.
Test the connection to a new namespace. In the Explorer window, under Authentication, right-click the new authentication resource and click Test.
You are prompted to enter credentials for a user in the namespace to complete the test.
Depending on how your namespace is configured, you can enter either a valid user ID and password for a user in the namespace or the bind user DN and password.
More information:
https://www.ibm.com/support/knowledgecenter/en/SSEP7J_11.0.0/com.ibm.swg.ba.cognos.inst_cr_winux.doc/t_ldapauthentication_process-element.html
To bind a user to the LDAP server, the LDAP authentication provider must construct the distinguished name (DN). If the Use external identity property is set to True, it uses the External identity mapping property to try to resolve the user’s DN. If it cannot find the environment variable or the DN in the LDAP server, it attempts to use the User lookup property to construct the DN.