by Roger·Comments Off on What queries are running now?
Product:
Microsoft SQL server 2016
Issue:
What happens on the SQL server now?
Solution:
Run this query:
SELECT r.start_time [Start Time],session_ID [SPID],
DB_NAME(database_id) [Database],
SUBSTRING(t.text,(r.statement_start_offset/2)+1,
CASE WHEN statement_end_offset=-1 OR statement_end_offset=0
THEN (DATALENGTH(t.Text)-r.statement_start_offset/2)+1
ELSE (r.statement_end_offset-r.statement_start_offset)/2+1
END) [Executing SQL],
Status,command,wait_type,wait_time,wait_resource,
last_wait_type
FROM sys.dm_exec_requests r
OUTER APPLY sys.dm_exec_sql_text(sql_handle) t
WHERE session_id != @@SPID -- don't show this query
AND session_id > 50 -- don't show system queries
ORDER BY r.start_time
3 types of rules which every consultant should know:
Allocation/Phase/Spread Rule – e.g. Allocate/phase/spread our budgeted sales across States based on the Actual Sales ratio.
Rolling Value Rule – e.g. Opening (Measure) is equal to the Closing of the prior period. Often used in the Balance Sheet or Depreciation rules.
Averaging Rule (C Level) – e.g. Averaging Percentages or Rates up all hierarchies within the cube.
As with TM1, and Platform Software in general, there are a million ways to do anything, so don’t worry if we don’t follow the methodology you are familiar with. That being said, these 3 TM1 rules are a great guide for any developer!
Allocation/Phase/Spread Rule – How to Spread a value Across Periods
This is a common requirement often seen in budgeting rules to allocate/phase/spread an annual budget across months based on Calendar Days, Working Days or Last Year’s Actual Values for the given account.
Here is a sample rule which will phase an annual budget across months based on the number of working days in each month.
There is a number of different ways to write this. For example, I could exclude the {} Months from my rule filter (scope) and filter using an ELISANC within an IF Statement to check that the month element of the current cell being calculated is a descendant of the ‘All Months’ Element but that would clutter the rule tracer when/if used later on the ‘Annual’ Element.
Feeder for Allocation/Spread Rule
Don’t you need a complex feeder with a rule like this?No. We only have to calculate a month if there is a value in the ‘Annual’ month (which is a posting element for annualised data) within the same year. Which means our feeder can simply be:
[‘Annual’,’Budget’,’$’] => [‘All Months’];
If you were writing this longhand, it would look like this:
Calculating a Balance Sheet, Net Book Value or Depreciation? This rule logic is bound to come up. This methodology is going to be slightly different depending on how you have your Time Dimension(s) set up within your cube.
Firstly there are even more possible solutions here, but we are aiming for a sustainable example. This means we will be avoiding DIMNM(DIMIX()-1) in favour of using attributes to help move around periods.
We’ll take a customer subscription calculation as our example. We’ll assume the cube for this rule has a separate Year and Month dimension.
Measures Dimension for Rolling Rule
Given a measures dimension which looks like this:
Closing Subscriptions
Opening Subscriptions
New Subscribers
Subscriber Churn (Displayed as a positive sign, aggregated with a -1 Weighting)
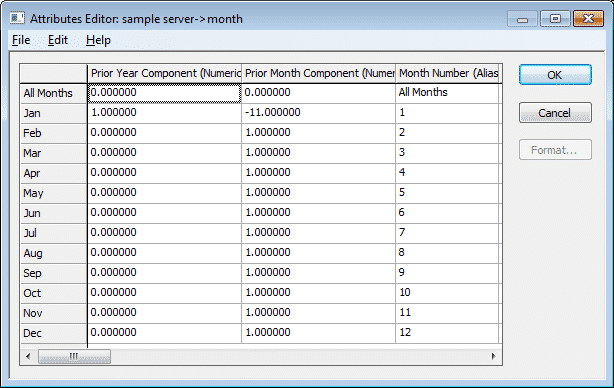
Attribute used on Month Dimension
We then have a clever little attribute table on the Month Dimension:
Sample Attribute Table to assist Rolling Value Rules.
Rolling Rule
A TM1 rule can then be written which looks like this:
This is what I would class as a bare-bones rule for Rolling a Value. This should go back as far as the Year dimension’s elements will go and has not potential to create a circular reference like DIMNM(DIMIX()-1) methodology.
If you want to post an opening amount into the first month and first year within your TM1 cube you can use an additional check to see if the generated Year exists using the DIMIX function, if it doesn’t a STET will make the cell editable.
Then, the feeders for this involve the same amount of coding, but the theory may be daunting for people still learning. This is because where the rule went back across time periods to get the value, the feeder has to go forwards across time periods to push the value into the rule calculation cell.
This could be written simpler if we didn’t piggyback the same “Prior Year” Attributes and instead added new “Next Year” Attributes. The above example feeder has a minimalistic approach to attributes but is paying for it in rule complexity.
I am also using a filter of each month because I have other N level elements in my month dimension which I don’t want this rule applied to.
Averaging Rule (C Level)
C Level (Consolidation Level) TM1 rules which do averaging are very similar to normal rules but the reason we have them listed is that people don’t realize until they have to write one that a (non-zero value) countermeasure is needed and you need to use a separate measure to perform the calculation in most cases.
I’m using price and not units for my product counter as I want to average all prices regardless of if the product is sold in a specific period. However, if I wanted an average price pro-rata units sold I would back solve my revenue equation like so.
TM1’s security can be as simple or as complex as you need. We tend to start with the broadest possible definition of security and then refine it down to the specific, to the cell if required. TM1 cell security places an overhead for your administrator to manage as it can get complex, not only within a cube but also with the interaction of it with element or dimension security. This guide will take you through how to create Cell Security the right way, that minimises the overhead on your server and administrator.
Standard “Create Cell Security Cube” Method
When you right-click on a cube and select Security, you are prompted to Create a Cell Security Cube. If you do this, it will create the cube that replicates the primary cube, but with the addition of the }Groups dimension. Let’s say you have a GL cube with Time, Version, Entity, Cost Centre, Account, and Measure. Using the automated method will give you those plus }Groups.
This is a dead-simple way to create a Cell Security cube and from it you can assign cell-level security. However, if you have, say six dimensions in the underlying cube, then you’ll have seven dimensions in the resulting cube. Great flexibility, because you can assign security to any corresponding intersection to the primary cube. Huge overhead through because you have to maintain all those intersections and if you want to go down the path of having rules manage the cell security, then it could have a big hit on performance.
Customised Cell Security Cube
So what do we do? We want a cell security cube that only has the dimensions you need to assign security for the primary cube. If, from our GL cube above, we only need Time, Version, and Account for administering security, then we create a security cube with only those plus the }Groups dimension. Administering a 4 dimension cube is very much easier than a 7 dimension cube!
Create a Custom Cell Security Cube
The only way two create a customised cell security cube is via a special TI. This TI contains just two lines, namely:
This has a set of simple binary switches that enable or disable a dimension from the primary cube. So obviously, our primary cube, the General Ledger cube, here has six dimensions, they are referred to here in the exact order they are in the primary cube and are separated by a colon (one of these “:”). Finally, the zero and one switches are contained inside a single inverted comma.
Running this TI will then create a cell security cube with only the required dimensions. So, with our dimensions above, we would end up with Time, Version, Account, and }Groups in the new cube. This corresponds with the 1’s in the command in the TI.
Rules
Once the Cell Security cube has been created, then we can assign rules to it. In the rule below we have six blocks. YOU can read the annotation in the rules. Note the last one is a catch-all with the scope of []. This sets it to be for all remaining intersections not caught by the rules above.
# Set Actuals to have Write access to future Weeks only
['Actual'] = S: IF ( ELLEV ( 'Time', !Time) = 0
,IF ( ATTRN ('Time', !Time, 'FY Week No') <= DB('System Control','Current Week','Value'), STET,'WRITE')
,CONTINUE
);
# Set Actuals to be Read for historic Periods (months) up until the most recent completed Month End
['Actual'] = S: IF ( ATTRS ('Time', !Time, 'Monthend Completed') @= 'Yes', STET,'WRITE');
# Set Budget to be all Read only
['Budget'] = S: 'READ';
# Set WEEKS for Active Forecast Versions to Write from Forecast Start Week onwards
[] = S: IF ( ELISANC ( 'Version', 'Active Forecast Versions', !Version ) = 1 & ELLEV ( 'Time', !Time) = 0
,IF ( ATTRN ('Time', !Time, 'FY Week No') < DB('System Control','Forecast Start Year-Week','Value'), STET,'WRITE')
,CONTINUE
);
# Set PERIODS for Active Forecast Versions to Write from Forecast Start Week onwards
[] = S: IF ( ELISANC ( 'Version', 'Active Forecast Versions', !Version ) = 1
,IF ( ATTRN ('Time', !Time, 'FY Period No') < ATTRN ( 'Time' ,ATTRS ( 'Time', DB('System Control','Forecast Start Year-Week','String'), 'Current Period'), 'FY Period No'), STET,'WRITE')
,CONTINUE
);
# Set ALL else to READ
[] = S: 'READ';
Deleting a Control Cube
Like other Control Objects, these cubes are special and cannot be elated by the normal right-click method. They must be deleted via a TI process as well. The TI just needs to contain the following
Obviously, if you run this, it will delete any data in the cube and any rules you have written against it. So copy the rules out first if you want to re-use them!
by Roger·Comments Off on How activate encryption of databases
Product:
Microsoft SQL Server 2019 Issue:
How active encryption on SQL servers databases?
Solution:
You need a folder on the SQL server to store the certificate, create a folder like e:\key and only give local administrators and the SQL service account access there.
You can use the same certificate for a group of SQL servers. Then it is possible to restore a database backup to one of the others server in that group – that use the same certificate.
One the first SQL server:
USE Master;
GO
CREATE MASTER KEY ENCRYPTION
BY PASSWORD='InsertStrongPasswordHere12!';
GO
CREATE CERTIFICATE TDE_Cert
WITH
SUBJECT='Database_Encryption';
GO
BACKUP CERTIFICATE TDE_Cert
TO FILE = 'e:\key\TDE_Cert.cer'
WITH PRIVATE KEY (file='e:\key\TDE_CertKey.pvk',
ENCRYPTION BY PASSWORD='InsertStrongPasswordHere12!')
Then on every other SQL server in the group , copy above files to the e:\key folder on the next server, and do this to activate TDE:
USE Master;
GO
CREATE MASTER KEY ENCRYPTION
BY PASSWORD='InsertStrongPasswordHere12!';
GO
USE MASTER
GO
CREATE CERTIFICATE TDE_Cert
FROM FILE = 'e:\key\TDE_Cert.cer'
WITH PRIVATE KEY (FILE = 'e:\key\TDE_CertKey.pvk',
DECRYPTION BY PASSWORD = 'InsertStrongPasswordHere12!' );
Then to enable the encryption, you need to run this on every database:
USE <DB>
GO
CREATE DATABASE ENCRYPTION KEY
WITH ALGORITHM = AES_256
ENCRYPTION BY SERVER CERTIFICATE TDE_Cert;
GO
ALTER DATABASE <DB>
SET ENCRYPTION ON;
GO
Replace <DB> with your database name.
Then the database and its coming backup files are encrypted. The Backup can only be restored on a server with the same certificate.
If you get an error like this:
The certificate, asymmetric key, or private key file is not valid or does not exist; or you do not have permissions for it.
Try by change the path from file=‘e:\key\TDE_CertKey.pvk’ to file=’e:/key/TDE_CertKey.pvk’
To see what databases are encrypted:
SELECT name,is_encrypted,* FROM sys.databases WHERE is_encrypted = 1
To check if the certificate is installed:
SELECT * FROM sys.certificates WHERE name = 'TDE_Cert'
Important: Keep your password and backup of the certificates files in a secure location. In case you need to restore a database to a new SQL server, this keys need to be restored first.
by Roger·Comments Off on Only import 10 rows from a text file
Product:
Microsoft SQL server 2016
Issue:
How to test import only 10 rows from a text file, with bulk insert command? To check if it works.
Solution:
BULK INSERT Salestable
FROM 'C:\temp\data.txt'
WITH (LASTROW = 10,
BATCHSIZE=250000,
MAXERRORS=2);
Enter LASTROW = 10 to only read ten rows of data from your data.txt file. Then you can check if you get the correct type of data to your table.
LASTROW = last_row
Specifies the number of the last row to load. The default is 0, which indicates the last row in the specified data file.
MAXERRORS = max_errors
Specifies the maximum number of syntax errors allowed in the data before the bulk-import operation is canceled. Each row that can’t be imported by the bulk-import operation is ignored and counted as one error. If max_errors isn’t specified, the default is 10.
BATCHSIZE = batch_size
Specifies the number of rows in a batch. Each batch is copied to the server as one transaction. If this fails, SQL Server commits or rolls back the transaction for every batch. By default, all data in the specified data file is one batch.
If you cancel a BULK INSERT, it will try to roll back all data, this will take time.
copy result to excel for further analysis, remove unused index and duplicates.
Run to see the biggest queries:
EXEC sp_BlitzCache @Top = 20, @BringThePain = 1;
Run this to see the size of index in one database:
SELECT OBJECT_NAME(IX.OBJECT_ID) Table_Name
,IX.name AS Index_Name
,IX.type_desc Index_Type
,SUM(PS.[used_page_count]) * 8 IndexSizeKB
,IXUS.user_seeks AS NumOfSeeks
,IXUS.user_scans AS NumOfScans
,IXUS.user_lookups AS NumOfLookups
,IXUS.user_updates AS NumOfUpdates
,IXUS.last_user_seek AS LastSeek
,IXUS.last_user_scan AS LastScan
,IXUS.last_user_lookup AS LastLookup
,IXUS.last_user_update AS LastUpdate
FROM sys.indexes IX
INNER JOIN sys.dm_db_index_usage_stats IXUS ON IXUS.index_id = IX.index_id AND IXUS.OBJECT_ID = IX.OBJECT_ID
INNER JOIN sys.dm_db_partition_stats PS on PS.object_id=IX.object_id
WHERE OBJECTPROPERTY(IX.OBJECT_ID,'IsUserTable') = 1
GROUP BY OBJECT_NAME(IX.OBJECT_ID) ,IX.name ,IX.type_desc ,IXUS.user_seeks ,IXUS.user_scans ,IXUS.user_lookups,IXUS.user_updates ,IXUS.last_user_seek ,IXUS.last_user_scan ,IXUS.last_user_lookup ,IXUS.last_user_update
Check the size of the index and the usages – have it been used?
Yes, all table should have a index – at least a clustered index.
But a data-ware house table, should maybe not have a index when you load a lot of data.
Index can be created after you have loaded a lot of data. This to speed up the process.
Correct made index make the SELECT faster. Any index in the target table, makes the INSERT slower.
You should have not too few, or too many index on a table to get the best performance.
To create a index:
CREATE TABLE dbo.TestTable
(TestCol1 int NOT NULL,
TestCol2 nchar(10) NULL,
TestCol3 nvarchar(50) NULL);
CREATE CLUSTERED INDEX IX_TestTable_TestCol1
ON dbo.TestTable (TestCol1);
You can also create index by right-click on table name – indexes – New Index.
Check if index exist, before you drop it;
IF EXISTS (SELECTnameFROM sys.indexes
WHEREname = N'IX_ProductVendor_VendorID')
DROPINDEX IX_ProductVendor_VendorID ON Purchasing.ProductVendor;
CREATE NONCLUSTERED INDEX IX_ProductVendor_VendorID
ON Purchasing.ProductVendor (BusinessEntityID);
Use ONLINE=ON to make the table readable when you create the index:
Columns with text, image, ntext, varchar(max), nvarchar(max) and varbinary(max) cannot be used in the index key columns.
It is recommended to use an integer data type in the index key column. It has a low space requirement and works efficiently. Because of this, you’ll want to create the primary key column, usually on an integer data type.
You should consider creating a primary key for the column with unique values. If a table does not have any unique value columns, you might define an identity column for an integer data type. A primary key also creates a clustered index for the row distribution.
You can consider a column with the Unique and Not NULL values as a useful index key candidate.
You should build an index based on the predicates in the Where clause. For example, you can consider columns used in the Where clause, SQL joins, like, order by, group by predicates, and so on.
You should join tables in a way that reduces the number of rows for the rest of the query. This will help query optimizer prepare the execution plan with minimum system resources.
If you use multiple columns for an index key, it is also essential to consider their position in the index key.
You should also consider using included columns in your indexes.
The clustered index defines the order in which the table data will be sorted and stored. As mentioned before, a table without indexes will be stored in an unordered structure. When you define a clustered index on a column, it will sort data based on that column values and store it. Thus, it helps in faster retrieval of the data.
There can be only one clustered index on a table because the data rows can be stored in only one order.
When you create a Primary Key constraint on a table, a unique clustered index is automatically created on the table.
The non-clustered index does not sort the data rows physically. It creates a separate key-value structure from the table data where the key contains the column values (on which a non-clustered index is declared) and each value contains a pointer to the data row that contains the actual value. It is similar to a textbook having an index at the back of the book with page numbers pointing to the actual information.
SELECT
t.NAME AS TableName,
i.name as indexName,
sum(p.rows) as RowCounts,
sum(a.total_pages) as TotalPages,
sum(a.used_pages) as UsedPages,
sum(a.data_pages) as DataPages,
(sum(a.total_pages) * 8) / 1024 as TotalSpaceMB,
(sum(a.used_pages) * 8) / 1024 as UsedSpaceMB,
(sum(a.data_pages) * 8) / 1024 as DataSpaceMB
FROM
sys.tables t
INNER JOIN
sys.indexes i ON t.OBJECT_ID = i.object_id
INNER JOIN
sys.partitions p ON i.object_id = p.OBJECT_ID AND i.index_id = p.index_id
INNER JOIN
sys.allocation_units a ON p.partition_id = a.container_id
WHERE
t.NAME NOT LIKE 'dt%' AND
i.OBJECT_ID > 255 AND
i.index_id <= 1
GROUP BY
t.NAME, i.object_id, i.index_id, i.name
ORDER BY
SUM(a.total_pages) DESC